-

Homogeneous: Definition, Types, and Examples
Continue ReadingHomogeneous Definition
Homogeneous can be defined as “the same” or “similar.” It can be used to describe things that have similar characteristics. Homogeneous substances, for example, are substances that are homogeneous in volume and composition across their whole volume. As a result, two samples obtained from two different portions of homogeneous mixtures and substances will have the same compositions and properties.
Homogeneous Etymology
The word homogeneous is derived from two Greek words: “homo” (meaning “the same”) and “genous” (meaning “kind”). As a result, homogenous refers to individuals who are all perceived to be the same, similar, or present in the same proportion.
What is Homogeneous Mixture?
Homogenous means “of the same sort” or “similar.” It’s the ancient name for homologous in biology, which means “having matching components, similar structures, or the same anatomical locations.” Homogenous is derived from the Latin homo, which means “same,” and “genous,” which means “kind.” homogenous is a variant. Heterogeneous is the antonym of homogeneous.
A mixture is formed when two or more components combine without undergoing any chemical changes. The mechanical blending or mixing of objects like elements and compounds defines a mixture. There is no chemical bonding or chemical change in this process.
As a result, the chemical characteristics and structure of the components in a combination are preserved. Size, form, colour, height, weight, distribution, texture, temperature, radioactivity, structure, and a variety of other characteristics all stay consistent throughout the homogeneous material.
When a pigment (such as ink) is combined with water, the resultant solution is highly homogeneous, which is a fairly common example of homogeneous in our daily lives. The colour combines equally with water, and any area of the solution has the same makeup.
Mechanical techniques can be used to separate them. Centrifugation, filtration, heat, and gravity sorting are some of the methods.
That’s all there is to it when it comes to the term’s use in chemistry or biology. The term “homogenous” is used in various research areas, such as ecology, to describe a population’s homogeneity.
A group of humans raised only by asexual reproduction – with identical genes and traits — is homogeneous, for example. Scientists hypothesized that if various orientations came from the same source, the cosmos would behave similarly. Evolutionary biology is another area of biology where the term homogeneous is employed.
Homogeneous is an ancient word for homologous, which refers to anatomical components that exhibit structural similarities, such as those generated by descent from a common ancestor.
The term homogeneous has been used widely in different fields of research, such as biology, chemistry, and ecology, but it is always used to describe organisms in a mixture who have the same properties.
In chemistry, homogeneous refers to a combination in which the ingredients are uniformly distributed. However, there are no chemical connections between them at the molecular level. Air is the most typical example of a homogeneous mixture in our environment.
Homogenous vs Heterogenous
A mixture, as previously stated, is the physical coming together of components (which, in chemistry, can be elements or compounds). There are two sorts of mixtures: homogeneous and heterogeneous.
The opposite of homogeneous is heterogenous (variant: heterogeneous). It refers to the components in a combination that have distinct properties (“hetero,” which means “different”). The most obvious example of a heterogeneous combination is oil and water, which form two distinct layers that are immiscible with each other, resulting in two distinct layers.
One of the most notable characteristics of heterogeneous mixes is that the particles are not dispersed equally throughout the mixture. Analysing the combination with the naked eye reveals the heterogeneous character of the mixture. In addition, the components of all heterogeneous mixes are not uniform.
Composition is similar in homogenous mixtures and dissimilar in heterogenous. In heterogenous mixtures, various phases are seen and single phase is seen in homogenous mixtures.
Substance can be sorted from each other by physical methods such as distillation, evaporation, centrifugation, chromatography, crystallization in both types of mixtures. Variation and a smaller number of species exist in homogenous mixtures, and the reverse is seen in heterogenous mixtures.
Although the concepts and compositions of homogeneous and heterogeneous substances are vastly different, both are prone to change depending on context and composition. Let’s take the example of blood. If we look at the blood with our naked eyes, it seems to be homogeneous.
Blood, on the other hand, has a variety of components under the microscope, including red blood cells, plasma, and platelets, showing that it is heterogeneous.
Homogeneous Examples
We come across numerous examples of homogeneous mixes and entities in our daily lives. In biology, a homogeneous population is one in which all of the individuals have virtually the same genetic makeup, as a result of some types of asexual reproduction.
Asexual reproduction produces homogeneous children who are identical to each other, including their parents.
Many animals, such as goat populations, look homogenous but are not because they reproduce through sexual reproduction.
According to experts, homogeneity reduces biodiversity, and as a result, the odds of early extinction due to environmental changes are significant. Animal cloning is a frequent example of a homogeneous population.
Dolly the sheep was the first mammal to be successfully cloned from a somatic cell in an adult.
Homogeneous species are those that exhibit indistinguishable characteristics and appear to be identical. Such species appear to have a lower level of biodiversity.
The diversity and frequency of species in a particular region and period, as well as the ecosystem’s homogeneity, may be quantified using a specific fundamental unit called species richness.
Species richness refers to the number of different species found in a specific ecological community. It displays the relative abundance of species rather than the total number of species in the environment. As a result, in a homogeneous environment, species richness will be lower, as high species richness indicates variability.
This is particularly evident in endemic species, which are species that have evolved through time in a specific geographic region and aren’t found anywhere else.
Grass, trees, ants, fungus, and certain animals are all instances of homogeneous in the ecosystem. Many endemic species found nowhere else in the world may be found in New Zealand.
Homogeneous used to be a very popular term in evolutionary biology to describe physically comparable features in various species, indicating a shared evolutionary origin.
The anatomical characteristics of several animal forelimbs are depicted. A similar evolutionary ancestor is shown by the identical forelimb bone components.
Homogeneous Summary
As a result of the preceding discussion, homogeneous substances are those that are uniform in volume and composition throughout. Homogeneous mixtures in chemistry have the same size, shape, colour, texture, and many other characteristics.
A solution that does not separate from each other over time is known as a homogeneous mixture. Homogeneous species are those that are genetically similar but lack biodiversity and species richness, as defined in biology and ecology.
Similarly, various solutions are widely used in our daily lives, and the blood and DNA in our bodies are both homogeneous. Heterogeneous mixes have properties that are the polar opposite of homogeneous mixtures.
As a result, the heterogeneous mixture contains non-uniform compositions and numerous phases that cannot be distinguished by physical changes. Furthermore, they are culturally varied and affluent.
Similarly, it has been demonstrated that both homogeneous and heterogeneous mixes are prone to change depending on their environment and composition. As a result, both heterogeneous and homogeneous mixes might be seen as equally important.
Homogeneous Citations
- Synthesis of Oxazolidin-2-ones from Unsaturated Amines with CO 2 by Using Homogeneous Catalysis. Chem Asian J . 2018 Sep 4;13(17):2292-2306.
- Recent Advances Utilized in the Recycling of Homogeneous Catalysis. Chem Rec . 2019 Sep;19(9):2022-2043.
- A review of thermal homogeneous catalytic deoxygenation reactions for valuable products. Heliyon . 2020 Feb 20;6(2):e03446.
Share
Similar Post:
-

Hyaline Cartilage: Definition, Function, and Examples
Continue ReadingWhat is Hyaline Cartilage?
Hyaline cartilage tissue is a kind of cartilage tissue that is also known as hyaline connective tissue or hyaline tissue. It’s the most prevalent kind of cartilage, with a lustrous, smooth look.
Cartilage is a tough and pliable connective tissue that protects bone ends, discs, and joints from wear and strain. At the embryonic stage, cartilage acts as the early skeletal structure in various animals, including humans.
The majority of it is replaced by bone as the animal grows. The cartilaginous skeleton of an adult cartilaginous fish (Chondrichthyes) is preserved. When compared to bone tissues, cartilage tissues are more flexible and elastic.
Around the bones of free-moving joints, hyaline cartilage is present. Articular cartilage is what this is called. The tissue present in the walls of the respiratory tract is another example of hyaline cartilage. The bronchi, nose, trachea rings, and rib tips all fall under this category.
Hyaline Cartilage Etymology
Hyaline cartilage is a kind of cartilage that has a lustrous, white, semi-transparent look with a little blueish tinge, according to biology. The name hyaline comes from the Greek word hyalos, which means “glassy,” suggesting the material’s gleaming, smooth look. The larynx, trachea, and bronchi are all places where it may be discovered.
Hyaline Cartilage Structure
Chondroblasts (or perichondrial cells) generate the extracellular matrix (or ground material), chondrocytes reside in gaps called lacunae, and collagen fibres make up cartilage.
Hyaline Cartilage Location
Mesenchymal cells, which are stem cells present in the bone marrow, give rise to it. Because it lacks blood vessels and nerves, hyaline cartilage has a relatively basic structure. It gets its nutrition from surrounding tissues via diffusion.
Hyaline cartilage has a gleaming, semi-transparent white look with a blueish tint. The name hyaline comes from the Greek word hyalos, which means “glassy,” suggesting the material’s gleaming, smooth look. Surprisingly, as the tissue matures, this look fades. Hyaline cartilage forms the initial skeleton in an embryo, which then changes as the embryo grows. Endochondral ossification is the process that causes this.
Fine type II collagen fibres, chondrocytes (matrix-producing cells), and the extracellular matrix make up hyaline cartilage (or ground substance). Collagen fibres of type II are thinner than collagen fibres of type I. Collagen types I, IV, V, VI, IX, and XI are also found in trace amounts and assist in holding the fibres together.
Glycosaminoglycans (GAGs), proteoglycans, and glycoproteins are abundant in the extracellular matrix, commonly known as the ground material. The extracellular matrix (ECM) covers the gaps between cells and fibres.
Long polysaccharides consisting of amino sugars that attract sodium and potassium ions are known as GAGs. These ions carry water with them. As a result, the amount of water in the extracellular matrix may be controlled.
Sulfated GAGs include chondroitin sulphate and keratan sulphate, whereas non-sulfated GAGs include hyaluronic acid. All of these substances can be present in cartilage’s extracellular fluid.
Proteoglycans and glycoproteins are a combination of amino acids and carbohydrates. They form a gel-like fluid that helps to absorb compression and tension by binding extracellular molecules and components together.
In hyaline cartilage, chondrocytes are the sole cartilage cells. These cells begin as chondroblasts (or perichondrial cells), which generate a cartilaginous matrix before becoming trapped inside it in tiny areas known as lacunae.
Chondrocytes are responsible for the development, repair, and maintenance of the extracellular matrix. Due to their restricted replication ability, chondrocytes have a limited healing capability. They seldom have cell-to-cell communication and are just concerned with preserving their local environment.
The perichondrium covers the hyaline cartilage in most cases. The perichondrium covers the articular cartilage on the ends of growing bones but not in adults. There are two layers to the perichondrium: an exterior layer and an interior layer.
The outer layer is fibrous cartilage that generates collagen fibres, whereas the inner layer contributes to cartilage development by producing chondroblasts or chondrocytes.
Hyaline Cartilage Examples
Hyaline cartilage is a kind of articular cartilage. It differs from normal hyaline cartilage in that the chondrocytes at the surface are flattened. It is 2 to 4 mm thick in people. There are no blood vessels, nerves, or lymphatics in it. It has a thick ECM but sparse chondrocytes.
The chondrocytes take on a more normal shape as they go deeper into the tissue. The cells are located in columns with a calcified matrix in the cartilage’s deep layers. Collagen strands create arches, which provide a robust structural arrangement that can bear pressure.
Type II collagen makes up articular cartilage, although it also contains tiny quantities of type VI, IX, X, and XI collagen.
Different zones make up the articular cartilage. The superficial zone is the first, followed by the intermediate transitional zone, the deep zone, and the calcified zone. There are three areas within each zone.
The pericellular region, territorial region, and interterritorial region are the three.
The superficial zone accounts for around 10% to 20% of the cartilage’s overall thickness. Here you’ll find collagen fibres II and IX. It has a significant number of chondrocytes with a flatter look.
The synovial fluid is in direct touch with the superficial zone, which shields the deeper layers from force and stress.
The intermediate zone runs parallel to the superficial zone and serves as a link between the two levels. This zone accounts for about 40-60% of the overall cartilage thickness.
It is made up of more dense collagen fibres and proteoglycans. The chondrocytes in this sample are spherical and in tiny numbers.
The purpose of the intermediate zone is to defend against compacting pressures. Following the intermediate zone, the deep zone gives the best resistance to compacting pressures. It has the largest proportion of proteoglycans and the least amount of water.
Collagen fibres are organised into columns and chondrocytes are positioned at right angles to the surface. It accounts for around 30% of the overall volume of articular cartilage.
Finally, the cartilage is attached to the bone via the calcified zone. It accomplishes this by attaching the deep zone collagen fibres to the subchondral bone.
Hyaline Cartilage Histology
Hyaline cartilage connective tissue is made up of cells and fibres inside an extracellular matrix, as previously stated. Hyaline cartilage histology explains the appearance of hyaline cartilage under a microscope.
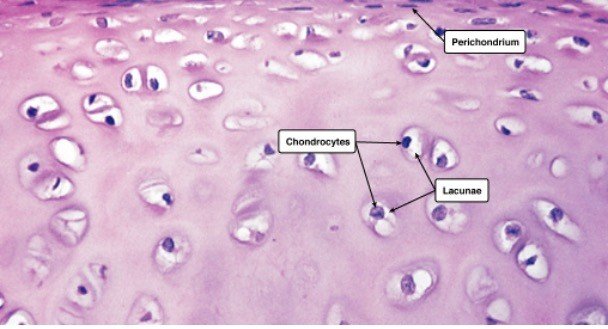
The shape of the chondrocytes might be spherical or angular. The cells in mature cartilage are found in isogenous clusters, each produced from a single progenitor cell. The matrix appears to be optically homogeneous and basophilic.
The explanation for this is that the collagen fibres are obscured by the large quantity of sulfated GAGs in the matrix. Because type II collagen fibres are so tiny, the extracellular matrix appears gleaming and smooth.
Within the extracellular matrix, there is no homogeneous distribution. As a result, the three fundamental zones are visible.
1. The capsular matrix, which is made up of a narrow zone around each lacuna. The greatest concentration of sulfated GAGs may be found here.
2. The capsular matrix is surrounded by a territorial matrix.
3. The interterritorial matrix, which is less basophilic due to a larger amount of collagen and a lower quantity of sulfated GAGs.
Under the microscope, hyaline cartilage may be examined using the hematoxylin and eosin (H & E) staining method as well as the Van Geison staining method. Picric acid and acid fuchsin are used in the Van Geison stain, which turns collagen red.
The staining grows lighter as it gets closer to the territorial matrix’s lacunae. The colour intensities are inverted in the H & E stained sections, although they have higher definition than the Van Geison stain.
The territorial matrix is black in hue, whereas the interterritorial matrix is much lighter. In the H & E technique, groups of chondrocytes may be detected surrounded by these darker regions. Because these chondrocytes come from the same progenitor, they form an isogenous group. Except for articular cartilage, the perichondrium surrounds the cartilage.
Hyaline Cartilage Function
Hyaline cartilage has a small number of fibres and offers a smooth surface for movement as well as a cushion to absorb stress at the point where the bones meet.
The major function of articular cartilage is to create a smooth surface that can resist friction and pressure caused by weight-bearing activities. It supports the softer tissues of the trachea and helps them to retain an open posture.
Hyaline cartilage’s primary purpose is to mechanically support the respiratory system, developing bones, and articular surfaces. The quality of our hyaline cartilage might deteriorate as we get older.
The number of chondrocytes in the surface layer of articular cartilage decreases as people become older, whereas the number of chondrocytes in the deeper layers rises. Additionally, as one gets older, the amount of proteoglycans in the extracellular matrix decreases.
Keratin sulphate levels are also up, whereas chondroitin sulphate levels are down. Hyaluronic acid volume increases as well. Due to its role as a shock absorber and frequent usage in daily activities, hyaline cartilage is prone to wear and strain. All of these characteristics can make hyaline cartilage more vulnerable to injury and illness than other cartilage forms.
Due to a lack of blood flow to the chondrocytes, cartilage tissues are prone to recovering slowly following an injury. This indicates that the matrix is taking a long time to develop. Furthermore, chondrocytes become trapped in lacunae and are unable to move to a damaged region. Scar tissue develops from damaged tissue.
Chondroitin sulphate, an anti-inflammatory mediator that decreases pain, plays a vital role in the extracellular matrix. According to research, its presence slows cartilage breakdown, preventing diseases like osteoarthritis.
Osteoarthritis develops when cartilage wears away, enabling the bones to rub against each other, producing sclerosis (hardening) of the subchondral bone (bone immediately under the cartilage) and inflammation of the synovial membrane, resulting in pain.
Hyaline Cartilage in Other Animals
The skeletons of animals in the Chondrichthyes class are entirely made of cartilage. Sharks and rays are excellent examples. Because cartilage is less thick than bone but yet offers strength, these creatures can move swiftly through the water without expending excessive effort.
Horseshoe crabs, snails, and cephalopods are instances of invertebrates possessing cartilage (predatory mollusks, e.g., octopus and squid). The branchial cartilage of the arthropod Atlantic horseshoe crab (Limulus polyphemus) is abundant in vacuolated chondrocytes, unlike that of any other arthropod.
Another kind of cartilage discovered in this species is endosternite cartilage. It has a higher fibrous content than vertebrate hyaline cartilage. It’s located near the ventral nerve cords and cartilage tissue of the gills.
The cranial cartilage of the octopus (a cephalopod) mimics hyaline cartilage and is one of the only hard sections of the octopus’s body. Cells move from the exterior to the core of the cartilage, causing it to expand. The cartilage of the common cuttlefish (Sepia officianalis) is fibrillar collagen. This cartilage has a development pattern similar to that of vertebrate cartilage.
The odontophore is a cartilage-formed feeding device in gastropods (snails, slugs, or whelks) that offers feeding support. The odontophore is a myoglobin-rich cartilage with a little portion of extracellular matrix and collagen around it.
Finally, cartilage supports the tentacles of feather duster worms (Sabellid polychaetes).
Types of Cartilage
There are three kinds of cartilage in the human body. The most prevalent, but also the weakest, kind of cartilage is hyaline cartilage. Fibrocartilage and elastic cartilage are the other two kinds of cartilage. The descriptions of each cartilage type may be found below.
i. Elastic Cartilage
Consider the distinctions between hyaline and elastic cartilage. Elastic cartilage (also known as yellow fibrocartilage) is a kind of cartilage that gives the body strength and elasticity.
Where can you find elastic cartilage?
The pinna, epiglottis, and laryngeal cartilage, as well as the auditory tube/eustachian tube, are all places where it can be found. Elastic cartilage provides greater elasticity while providing support. A thick network of elastin fibres can be found within it. It doesn’t offer any protection against mechanical stress or compression.
ii. Fibrocartilage
Fibrocartilage connective tissue is a fibrous tissue that is thick, flexible, and supports cartilage.
Where can you find fibrocartilage?
The intervertebral discs of the spine, the jaw, the knee, and the wrist are all places where fibrocartilage can be found. Large bundles of type I collagen may be seen in this fibrocartilage tissue. It is the most durable cartilage.
Fibrocartilage provides resistance to weight-bearing and pressure stresses. Fibrocartilage may be classified into four distinct categories.
1. Intra-articular fibrocartilage is the first group. This works as a cushion between joints that are subjected to a lot of stress and movement. The menisci of the knee are one example.
2. Connecting fibrocartilage, which is present in joints with restricted mobility, such as the intervertebral discs, is the second category.
3. Stratiform fibrocartilage is a kind of fibrocartilage that coats the bone grooves where tendons and muscles are present.
4. Finally, certain articular cavity borders are surrounded by circumferential fibrocartilage, which protects their edges. One acetabular labrum is an example (lining the hip socket).
Elastic cartilage, hyaline cartilage, and fibrocartilage are the three kinds of cartilage. Cartilage is a connective tissue defined by an extracellular matrix rich in chondroitin sulphate and chondrocytes as the cellular component. The most prevalent kind of cartilage is hyaline cartilage.
Hyaline Cartilage Summary
Overall, cartilage is a crucial structural component of the body that may be found in vertebrates and some invertebrates. It is a strong but soft tissue that supports, stretches, and strengthens the body.
Hyaline cartilage between joints demonstrates the importance of cartilage. The cartilage thins as we age, causing inflammation and bone friction.
Researchers in this field are working on studies that will help us better understand the mechanisms that contribute to these diseases and discover strategies to combat/treat/prevent them.
Hyaline Cartilage Citations
Share
Similar Post:
-

Hyperosmotic: Definition, Types, and Examples
Continue ReadingHyperosmotic Definition
The word “hyperosmotic” comes from two Greek words: “hyper,” which means “excess,” and “osmos,” which means “thrust” or “push.” A solution that exerts more thrust or pushes through a membrane is referred to as hyperosmotic.
To fully comprehend this concept, we must first comprehend that a solution is created by combining two components, namely a solute and a solvent. Sugar is the solute and water is the solvent in an aqueous sugar solution, for example.
(1) of, pertaining to, or characterised by an elevated osmotic pressure (usually higher than the physiological level);
(2) a state in which the total amount of permeable and impermeable solutes in a solution is larger than that of another solution.
What is Hyperosmotic?
In each system, the quantity of solute in a solution eventually dictates the direction of solvent flow. It is a well-known fact that a concentration difference causes the formation of a concentration gradient, which pushes the migration of molecules from a higher concentration to a lower concentration.
Osmosis is a phenomenon that happens when a concentration gradient causes the solvent (water) molecule to flow through a semi-permeable membrane.
As a result, a hyperosmotic solution is one that has a greater concentration of solute than a comparable solution. Seawater, for example, is hyperosmotic when compared to freshwater or tap water. A freshwater cell gets caught to a hyperosmotic environment when it is placed in a beaker with seawater.
The osmolarity of a solution is the number of solute molecules per volume or weight of the solution. The osmotic pressure exerted by a solution is controlled by its osmolarity. This is especially significant in biological systems when two solutions are separated by a membrane that is typically semi-permeable.
As a result, osmolarity can influence the flow of molecules in a biological system across a biological membrane. Maintaining cellular homeostasis requires the flow of molecules across the biological membrane. As a result, osmolarity is important for cellular homeostasis.
The osmolarity of human serum is kept within a narrow range of 285–295 mOsm/kg. Isotonicity refers to the fact that the majority of human body cells share a comparable osmolarity. Hypertonic and hypotonic fluids are defined as having greater or lower osmolarity than human serum, respectively.
The growth of osmotic pressure, which finally culminates in the creation of osmotic stress in a biological system, is caused by a variation in osmolarity. The pressure or push provided to the solvent molecules to prevent them from passing through the membrane is known as osmotic pressure.
It is critical to recognise at this point that tonicity and osmolarity are not the same thing and should not be confused. Isotonic solutions are not always isosmotic, and vice versa. In the same way, a hyperosmotic solution isn’t always a hypertonic solution. To comprehend this, we must first comprehend the idea of tonicity.
Only non-penetrating solutes have tonicity, which is always dependent on the comparative solution. An isotonic sucrose solution for a mammalian cell will be isotonic, whereas a hypotonic sucrose solution for a plant cell will be hypotonic.
This is because sucrose cannot permeate through a mammalian cell because it lacks transporters, but sucrose can permeate through a plant cell since transporters are present. As a result of sucrose’s non-permeability in mammalian cells, the isotonicity of isotonic sucrose solution in mammalian cells.
It’s crucial to remember that tonicity is governed only by non-penetrating solutes to grasp this. Hypotonic solutions have a lower concentration of non-penetrating solutes than hypertonic solutions. A 5 percent dextrose solution with no non-penetrating solutes is a classic example of a hypotonic solution.
Water movement occurs when a cell is put in a hyperosmotic yet hypotonic solution, such as 10% dextran. As a result, a solution might be hyperosmotic and hypotonic at the same time.
When the extracellular fluid’s osmolarity exceeds that of the intracellular fluid, the cell is said to be exposed to a hyperosmotic environment and will undergo hyperosmotic stress. When the extracellular fluid has a greater osmolarity, it causes water to flow out of the cell, causing cell shrinkage and finally dehydration.
A cell’s exposure to hyperosmotic fluid can be extremely harmful to it. Such cells will have to cope with water efflux, which will disturb a variety of cellular functions, including DNA synthesis and repair, protein translation and degradation, and mitochondrial dysfunction. The cell shrinks and the nucleus convexes as a result of the hyperosmotic state.
Apoptosis, which leads to cell death, is induced by cell shrinkage. When the extracellular fluid’s osmolarity is less than that of the intracellular fluid, the cell is said to be in a hypoosmotic environment. There will be an influx of water/solvent in such an atmosphere.
Physiological Importance of Hyperosmotic Property
The human body is very adaptable to such changes, and in order to do so, cells engage in osmo-adaptive reactions, in which they attempt to adjust to such changes and restore homeostasis. Failure to re-establish homeostasis, on the other hand, frequently leads to a sick or inflammatory state in the body.
Osmolarity imbalances may be harmful to cells and biological processes, and can even lead to illness. The kidney, in conjunction with the antidiuretic hormone arginine vasopressin (AVP) produced by the posterior pituitary, regulates osmolarity homeostasis in the human body.
The release of AVP from the pituitary gland is triggered by an increase in plasma osmolarity. AVP then works on the kidney, increasing the distal tubule’s membrane permeability and therefore increasing tubular reabsorption of water from the kidney. The kidney controls both the quantity of solute and water in the urine.
The urine output might have a low osmolarity (50 mOsm/L) or a high osmolarity (1200-1400 mOsm/L) depending on the body fluid state. When the body has an overabundance of water and the extracellular fluid has a low osmolarity, low osmolarity urine is produced. The urine is hypoosmotic in this situation.
Hyperosmotic urine, on the other hand, is formed when the body is dehydrated and the extracellular fluid has a high osmolarity. Higher osmolality in body fluids causes the pituitary to produce AVP, which promotes tubular water reabsorption from the kidney.
As a result of water reabsorption, the amount of water in the urine output is decreased, resulting in highly concentrated urine, also known as hyperosmotic urine. Osmolarity changes have also been linked to the initiation of inflammatory processes in the body.
Hypernatremia, heat stroke, diabetes, tissue burns, dehydration, asthma, cystic fibrosis, and uremia have all been linked to high extracellular fluid osmolarity. TNF, IL1, IL6, IL8, and IL18 are pro-inflammatory cytokines that have been linked to hyperosmotic stress-related diseases.
Consider the following example: The tubular fluid in the kidneys is:
1. When it’s at the start of the Henle loop, it’s iso-osmotic (to plasma).
2. When it’s at the end of the loop, it’s hyperosmotic (to plasma).
3. When it departs the loop, it becomes hypo-osmotic (to plasma).
Therapeutic Applications of Hyperosmotics
In the treatment of glaucoma, hyperosmotic drugs are utilised. Glaucoma is a vision or ophthalmic disease in which the intraocular pressure rises (IOP). A rise in IOP, along with impaired vision, is a very unpleasant condition for the patient.
Hyperosmotic drugs lower IOP by creating an osmotic gradient between the blood and intraocular fluid compartments, causing ophthalmic fluid to flow into the bloodstream. When glaucoma does not react to carbonic anhydrase inhibitors given topically or systemically, this treatment strategy is chosen. Hyperosmotic drugs, on the other hand, have a short duration of effectiveness and might cause systemic adverse effects.
IOP is raised in glaucoma due to the presence of vitreous fluid in the eye. The osmolality of the intravascular fluid rises when hyperosmotic drugs are administered (hyperosmolarity).
The ocular barrier, on the other hand, prevents these substances from penetrating into the vitreous fluid. The osmotic gradient is created as a result of this. As a result, fluid from the vitreous outflow enters the vascular fluid. As a result, the patient’s IOP is lowered due to the reduced quantity of vitreous fluid.
The use of hyperosmotic drugs in glaucoma patients has been shown to result in a 3-4 percent decrease in IOP. Molecular weight, dosage, concentration, rate of administration, route of administration, excretion rate, distribution, and ocular penetration are all parameters that influence the effectiveness of these drugs.
Glycerin, urea, isosorbide, mannitol, and other hyperosmotic are examples of hyperosmotic used in glaucoma treatment. These agents can be used topically, intravenously, or orally. However, systemic (parenteral) or oral administration of these drugs may have undesirable side effects.
Hyperosmotic drugs are often used to treat eye illnesses, such as glaucoma, as well as their dosage and possible adverse effects.
Hyperosmotic drugs are also used to improve vision in individuals with corneal edoema, where the agents produce temporary dehydration to reduce the cornea’s oedematous state. Hyperosmotic drugs are also used to treat cerebral edoema, in addition to ocular edoema.
Hyperosmotic drugs can also be used as a plasma volume expander in the treatment of hypovolemic bleeding.
An efficient plasma expander has been reported to be a combination of 7.5 percent sodium chloride and 6 percent dextran-70. This combination of hyperosmotic drugs (NaCl and dextran) has also been shown to decrease acute hypotension and head injury mortality.
The use of a hyperosmotic drug has been shown to have fast cardiovascular effects, including an increase in cardiac parameters such as arterial pressure, cardiac output, plasma volume, cardiac contraction, mean circulatory systemic pressure, and oxygen supply and consumption.
Hyperosmotic Stress in Plants
Plants, like mammals, are susceptible to physiological disturbances caused by hyperosmotic stress. Hyperosmotic stress is a common manifestation in plants as a result of hyperosmotic conditions (when the osmolarity outside is higher than the inside of the cell).
High salt concentrations in the soil, as well as dryness, are the typical culprits. When this happens, the plants respond by changing their genetic expression, producing intracellular osmolytes, and active endocytosis, as well as ion sequestration through vacuolar transport, to counteract the water outflow and subsequent decrease in cell volume.
If the severe disturbance is not corrected quickly, the plant cell may perish due to a loss of turgor pressure and the collapse of the plasma membrane.
Hyperosmotic Citations
- Hyperosmotic stress response: comparison with other cellular stresses. Pflugers Arch . 2007 May;454(2):173-85.
- Response to hyperosmotic stress. Genetics . 2012 Oct;192(2):289-318.
- Hyperosmotic phase separation: Condensates beyond inclusions, granules and organelles. J Biol Chem . Jan-Jun 2021;296:100044.
Share
Similar Post:
-

Mutagen: Definition, Types, and Examples
Continue ReadingMutagen Definition
A mutagen is a chemical or agent that alters the DNA sequence by causing DNA impairment. Mutation is the term for this change in DNA sequence.
What is a Mutagen?
A mutagen is a substance that induces mutations in living organisms. Physical, chemical, and biological mutagens are all types of mutagens.
Mutagenicity refers to a substance’s ability to cause changes in the base pairs of DNA, also known as mutation. The hereditary substance of a live cell is DNA. DNA is a polynucleotide that consists of many nucleotide units. Nitrogen-containing nucleobases (cytosine [C], guanine [G], adenine [A], or thymine [T]) are covalently bonded to sugar (typically deoxyribose) and a phosphate group to form these units. All of a cell’s genetic information is encoded in the standard arrangement of nucleic acid bases.
A mutagen alters the pattern and sequence of nucleic acid bases in DNA, resulting in alterations in the protein that results. Depending on whether the alterations occur in somatic or germline cells, they may be inheritable or non-inheritable.
UV radiation, X-rays, reactive oxygen species, alkylating agents, base analogues, transposons, and other mutagens are only a few examples.
Types of Mutations
Mutations are categorised as follows, depending on which cells are impacted by the mutagen:
i. Somatic Mutations
These are mutations that arise in a living being’s non-reproductive cells (somatic cells). Due to the body’s reparative and compensatory processes, many forms of somatic mutations may not develop to impact an individual. A somatic mutation, on the other hand, changes the cell’s cell division processes, can eventually lead to the development of malignant cells or tissue.
ii. Germ-line Mutations
These mutations can happen in gametes or the reproductive cells that make gametes or sex cells. These mutations are inherited and passed on to the following generation in all of their cells (both somatic and germ-line). Chemicals have been categorised based on their ability to cause mutations in germline cells.
1. Chemicals that are known or proved to induce germ-line heritable mutations based on epidemiological data are classified as 1A chemicals.
2. Chemicals classified as 1B induce germ-line heritable mutations based on mutagenicity studies performed on in vivo mammalian germ cells or somatic cells.
3. Chemicals classified as 2 are compounds that, based on in vitro studies or in vivo somatic cell mutagenicity or somatic cell genotoxicity testing in animals, are thought to induce germ-line heritable mutations.
Mutagens are known to enhance the frequency of mutations beyond what occurs naturally. However, it is critical to note that not every DNA impairment or damage may be classified as a mutation. During the cell-repair process, DNA polymerases remove the broken or changed parts of DNA in the vast majority of cases. Mutations induced by mutagens, on the other hand, tend to evade this cellular repair mechanism, resulting in a ‘permanent’ alteration in the DNA.
Type of DNA Mutations
1. Base Substitutions: Single-base substitutions are referred to as “point mutations.” Silent, missense, and nonsense mutations are the most frequent kinds of mutations.
a. Silent Mutations: The substitution of a nucleotide in the codon’s third position. As a result, there’s a good chance that an identical codon will be created, coding for the same amino acid sequence. As a result, there is no silent mutation due to a change in the gene sequence.
b. Missense: A base substitution that causes a gene sequence to code for different amino acids and, subsequently, a new polypeptide sequence to be generated.
c. Nonsense: This mutation is defined as a base substitution that results in the development of a gene sequence that truncates translation or a change that results in the generation of a stop codon that finally results in the formation of a non-functional protein.

2. Deletion: Deletion of one or more base pairs in DNA, as the term implies. When one or more base pairs are lost or removed from the DNA, this might cause a frameshift.

3. Insertions: Frameshifts can also be caused by the insertion of extra base pairs into the DNA. However, whether or whether the addition of base pairs occurs in multiples of three base pairs will determine the frameshift.
Any agent (physical or environmental) that can cause a genetic mutation or enhance the rate of mutation (biology definition). Silent mutations occur when a mutation occurs in the non-functional section of the DNA, whereas deadly mutations occur when a mutation occurs in the actively transcribed area of the DNA, resulting in cell death.
The biological impact of these DNA changes is dictated by the location of the change in the DNA, the time of mutation throughout the cell cycle, the length or magnitude of the change, and any previous mutations.
Molecular Mechanisms of Mutagenesis
Mutagens operate on DNA in a number of ways, with the following being some of the most prevalent mechanisms for mutagenesis:
DNA Damage: The particular sequence of purine (guanine and adenine) and pyrimidine (cytosine and thymine) bases connected by hydrogen bonding, i.e. guanine (G)/cytosine (C), that encodes all of a living being’s genetic information. DNA damage can be caused by a mutagen that changes these base sequences.
Spontaneous Damage: The production of apurinic/apyrimidinic (AP) sites is caused by spontaneous base deamination, hydrolysis of purines or pyrimidines, and the deoxyribose link. The sugar-phosphate backbone is eventually exposed to DNA strand breaking as a result of this. There are also tautomeric variants of the bases, which can lead to multiple base mispairing.
Chemical Adducts: Electron-deficient species, or extremely reactive electrophiles, are found in several chemical mutagens. These reactive mutagens can create covalently bound nucleophilic adducts inside DNA, which can stabilise the purine/pyrimidine bases’ alternate tautomeric configurations. The base pair coding will ultimately change as a result of this.
This will result in erroneous base pair information being transcribed, as well as increased vulnerability to DNA hydrolysis and the creation of AP sites. Additionally, some mutagens may increase DNA inter- and intrastrand cross-linking, which prevents DNA strand separation. As a result, difficulties arise during the replication, transcription, and repair of DNA.
Oxidative Damage: Mutagens can cause oxidative stress, which causes free radical production (oxygen or nitrogen). These free radicals might be hydroperoxide, hydroxyl, or superoxide moiety, and are extremely reactive molecules with unpaired electrons. These free radicals interact with DNA, causing DNA strands to break, bases to hydrolyze, or lesions to form on the DNA strand.
DNA Intercalation: Some mutagens bind to the complementary strands of DNA and intercalate between them. The hydrogen bonding between the base pairs is disrupted as a result of this. Intercalation like this eventually leads to misread or erroneous replication and transcription processes.
Metabolic Activation: The normal metabolic process, which takes place mostly in the liver, is divided into two stages: stage I and stage II. These metabolic processes seek to increase the solubility of unwanted chemicals in order to remove them from the body. The hydroxylation process takes place in Stage I, which is carried out by the cytochrome P450 enzyme system.
In Stage II, polar groups are added by the use of glutathione S-transferase, glucuronide transferase, microsomal epoxide hydrase, or acetyltransferase. The bulk of mutagens are inactivated during stage II, although some enzymes, such as flavin monooxygenase and prostaglandin H synthase, have been shown to activate mutagens.
Types and Examples of Mutagens
Mutagens can be divided into three groups;
i. Physical Agents
a. Radiation
Radiation was the first agent to be identified as mutagenic. UV rays, X-rays, alpha rays, and neutrons, among other ionising and non-ionizing radiation, have been discovered to be mutagenic. The majority of these radiations cause fatal (i.e., cell death) or sub-lethal (i.e., cell dysfunction) effects by directly destroying DNA or nucleotides via:
1. inducing DNA or protein cross-linking
2. chromosomes are broken
3. strand breakage or chromosomal loss
4. base deletion/DNA strand breaks at a molecular level
Ionizing or high-energy radiation, such as X-rays and-rays, works primarily on dividing cells and damages more than just DNA. Their impact also affects lipids and proteins. These rays produce free radical molecules that damage DNA or chromosomes.
X-rays with a dosage of 350-500 rems are deemed deadly because they cause phosphodiester links to break, causing DNA strands to break. UV rays, unlike X-rays, are non-ionizing radiation because they contain less energy. Sterilization and decontamination processes frequently use them.
UV rays cause mutagenesis through a variety of processes, including base deletion, strand breaking, cross-linking, and the creation of nucleotide dimers.
UV A, UV B, and UV C are the three kinds of UV radiation. UV-A is a kind of UV radiation with a wavelength of 320nm (near-visible range) that is known to cause pyrimidine dimerization. This kind of pyrimidine dimerization causes a change in the DNA structure, which prevents the replication fork from forming during the replication process.
Dimerization may cause health problems. UV-B, which has a wavelength of 290-320nm and is particularly deadly to DNA, has a wavelength of 290-320nm. UV-C radiation, which has a wavelength of 180-290nm, is the most damaging and carcinogenic. The ozone layer absorbs the majority of UV-C light.
b. Heat
Temperatures exceeding 95°C are dangerous for DNA. The phosphodiester bonds in DNA break at 95°C, causing the DNA strand to break. As a result, heat causes DNA to break.
ii. Chemical Agents
a. Base Analogues
They are agents that are structurally identical to bases, such as purines and pyrimidines. 5-Bromouracil and aminopurine are the most frequent base analogues that are considered chemical mutagens. Base analogues are integrated into the DNA structure during replication due to structural similarities between these agents and DNA bases.
Aminopurine is identical to adenine and may couple with C or T to create a base pair (though base pairing with C is rare). Tautomeric variants of 5-bromouracil exist. Each tautomeric molecule binds to a distinct base pair. The keto form of 5-bromouracil substitutes thymine in DNA and creates a base pair with adenine, whereas the enol tautomeric produces a base pair with guanine.
As a result, 5-bromo uracil causes a point mutation. As a result, DNA containing 5-Bromouracil switches base pairs from A-T to G-C or from a G-C to an A-T during replication, depending on the tautomeric form.
b. Intercalating Agents
They are compounds with a hydrophobic heterocyclic ring structure that closely resembles the ring structure of base pairs. These agents embed themselves in the DNA helix, causing mutations, most often frameshift mutations, by interfering with replication, translation, and transcription.
Intercalating chemicals include ethidium bromide, proflavine, acridine orange, actinomycin D, or daunorubicin, among others. Daunorubicin, Epirubicin, Epirubicin, and Mitoxantrone are some of the most commonly used anti-cancer or anti-antineoplastic medicines.
c. Metal Ions
Mineral ions such as nickel, chromium, cobalt, cadmium, arsenic, chromium, and iron produce reactive oxygen species (ROS) that induce DNA hypermethylation, increasing DNA damage and obstructing DNA repair.
d. Alkylating Agents
These chemicals cause DNA damage by causing alkyl groups to form in the DNA. The insertion of alkyl groups causes an increase in ionisation, which causes base-pairing mistakes and eventually holes in the DNA strand. Ethylnitrosourea, mustard gas, vinyl chloride, Methylhydrazine, Busulfan, Carmustine, Lomustine, Dimethyl sulphate, Temozolomide, Dacarbazine, Ethyl ethane sulphate, and Thio-TEPA are some of the most frequent alkylating agents.
These chemicals can be eliminated from the DNA during the DNA repair process via the depurination procedure. Depurination is a procedure that is not mutagenic.
iii. Biological Agents
a. Transposons and Insertion Sequences
They are DNA units that perform self-directed DNA fragment displacement and multiplication. Insertion sequences, or IS, are the simplest form of transposons (10-50 base pairs long). IS and transposons are both referred to as jumping genes because they travel across DNA.
The introduction of transposons into chromosomal DNA causes the genes’ functioning to be disrupted. IS and transposons both include information for the enzyme transposases, which aids in the creation of new transposition sites in DNA.
There are three types of transposons that are commonly found:
1. Replicative Transposons: These are transposons that keep the original locus but replicate it.
2. Conservative Transposons: The original transposon translocates itself into these transposons.
3. Retrotransposons Transpose: These transposons go via RNA intermediates to reach their destination.
b. Viruses
The insertion of viral DNA into the genome may cause genetic function to be disrupted. The Rous sarcoma virus, for example, has been known to cause cancer. Viruses can therefore be regarded as mutagenic.
c. Bacteria
Bacteria that cause inflammation, such as Helicobacter pylori, create reactive oxygen species, which cause DNA damage and a reduction in DNA repair. This raises the likelihood of a mutation.
Mutagen vs Carcinogen
It’s critical to know the distinction between mutagens and carcinogens at this point. These two words are often used interchangeably since they are so closely related. These are, however, two distinct words.
Mutagens are substances that cause heritable or non-heritable changes in DNA.
Carcinogens are substances that cause uncontrolled cell division, resulting in the formation of tumours that may or may not be malignant.
Though both words are commonly linked, mutagenic chemicals can cause changes in a cell’s genetic material, which can lead to carcinogenesis. As a result, carcinogenesis might be a side effect of mutagen-induced mutagenic alterations.
Mutagens have also been linked to an increase in the frequency of carcinogenic occurrences.
It’s also crucial to remember that while certain mutations aren’t life-threatening, carcinogenesis produces life-threatening consequences.
Teratogens is a word that is commonly used interchangeably with teratogens. Teratogens are substances that can cause abnormalities or birth defects in a foetus while having no impact on the mother. Teratogenic chemicals include ethanol, mercury compounds, phenol, lead compounds, carbon disulfide, xylene, and toluene.
Thalidomide is the most well-known teratogenic medication, which was first administered to pregnant women in the early 1950s for morning sickness. Thalidomide caused extensive congenital abnormalities such as missing legs, limbs, and ears, among other things. As a result of these numerous incidents, the medication was withdrawn from use.
Thalidomid was reintroduced for the treatment of myeloma and leprosy in the early 2000s. Phenobarbital, Valproic acid, Tretinoin, Tetracyclines, fluoroquinolones, warfarin, Propylthiouracil (PTU), methimazole (MMI), carbimazole, high dosages of Vitamin A, Diethylstilbestrol, and other teratogenic medicines are also well-known. Diethylstilbestrol has been found to be both carcinogenic and teratogenic.
All three types of agents, i.e. mutagens, carcinogens, and teratogens, have one thing in common: they are all very powerful and exhibit their impact at very low doses.
Effects of Mutagens
Changes in a cell’s genetic makeup are known as mutations. These mutations can be fatal or non-lethal, and they can also be inheritable or non-inheritable. Mutations, in any event, change the genetic makeup of a population.
Many mutations can result in a variety of illnesses. Certain mutational illnesses are passed down through the generations and are caused by mutations in the germ cells.
Sickle cell anaemia is a condition caused by a single missense mutation in the -globin gene at codon 6 in germ cells. The glutamic acid at position 6 in the normal protein is replaced by valine in this mutation. This alteration has a significant impact on haemoglobin, the oxygen-carrying protein. The oxygen-carrying capacity of mutant haemoglobin is greatly decreased, and erythrocytes become stiff, resulting in painful blood cell passage, capillary blockage, and tissue injury.
The faulty erythrocytes are resistant to malaria, so the mutation has been passed down through the African population. Retinoblastoma or retinal tumours in children, Tay-Sachs disease, phenylketonuria, colorblindness, and cystic fibrosis are some of the illnesses caused by mutation.
It’s crucial to remember, though, that mutations aren’t always fatal or detrimental. The vast majority of mutations are completely harmless. In truth, mutations are to blame for the changes in the gene pool that have led to the development of life on the planet throughout the centuries.
Populations with a wide range of mutations have been able to withstand natural selection and adapt to meet their needs. Populations that were unable to adapt or change in response to changes in their surroundings eventually died out.
Mutation is, in reality, the initial step toward evolution. One such evolutionary genetic step is the development of coat colour by insects and animals for concealment. Apolipoprotein A1-Milano, a mutant protein Apolipoprotein, was discovered in a tiny Italian town with an unusual advantageous mutation (or Apo A1M).
Normal apolipoprotein is the protein responsible for cholesterol transport. Apo A1M, a mutant form of Apolipoprotein, not only eliminates cholesterol but also dissolves plaques and possesses antioxidant properties. As a result, the Italian community with the altered Apo A1M gene is protected against heart disease.
Mutagen Citations
- Mutagen formation during commercial processing of foods. Environ Health Perspect . 1986 Aug;67:75-88.
- Mutagenicity and genotoxicity studies of aspartame. Regul Toxicol Pharmacol . 2019 Apr;103:345-351.
- Is fluoride a mutagen? Sci Total Environ . 1988 Jan;68:79-96.
- Mutagen sensitivity assays in population studies. Mutat Res . 2003 Nov;544(2-3):273-7.
- Mutagen sensitivity: a genetic predisposition factor for cancer. Cancer Res . 2007 Apr 15;67(8):3493-5.
Share
Similar Post:
-
Myocardium: Definition, Function, and Examples
Continue ReadingMyocardium Definition
The myocardium is the muscular layer of the heart. It consists of cardiac muscle cells (cardiac myocytes [also known as cardiac rhabdomyocytes] or cardiomyocytes) arranged in overlapping spiral patterns.
What is Myocardium?
It is the heart’s muscular middle layer, wedged between the epicardium and the endocardium. It is sometimes referred to as the cardiac mass. Cardiac muscle cells (also known as heart muscle cells, cardiomyocytes, cardiac myocytes, or cardiac rahbdomyocytes) and fibroblasts make up the myocardium.
The heart is the human body’s primary circulatory organ, which pumps blood throughout the body. The heart is housed in the “pericardium,” a thin fibroelastic, double-layered, fluid-filled sac. The outer fibrous or parietal pericardium and the interior serous or visceral pericardium are the two layers of the pericardium.
Myocardium Etymology
The middle layer of the heart’s wall; the muscular material of the heart lying in the middle, i.e. between the epicardium and the endocardium (biology term). Mûs + karda are two Ancient Greek words that mean “muscle” and “heart,” respectively.
Heart Structure
The heart’s walls are divided into three layers:
1. Epicardium: The epicardium is the heart’s outermost layer. Underneath the mesothelial cells lie connective and adipose tissues. The visceral layer of the serous pericardium is likewise made up of this layer. There are coronary arteries and veins, lymphatic vessels, and nerves beneath the epicardium.

2. Myocardium: This is the heart’s muscle layer, which is responsible for the heart’s pumping activity. It accounts for 95 percent of the mass of cardiomyocytes and is the thickest layer in the heart wall. The pressure present in each chamber determines the thickness of the myocardial layer. As a result, the issue arises as to which of the four chambers of the heart has the thickest myocardium. The atrium has a thin myocardial layer, whereas the ventricles, particularly the left ventricle, have the thickest myocardium.
In fact, the left ventricular myocardium in mature animals is three times thicker than the right ventricular myocardium. This is fascinating, and it raises the question of why the left ventricle is thicker than the right. Because the left ventricle pumps blood across the body and also against the higher pressure in contrast to the right ventricle, the left ventricle’s walls are thicker than the right ventricle’s.
3. Endocardium: This is the deepest layer of the heart that borders the inner wall as well as the heart valves. The endocardium is further split into two layers:
(a) an inner endothelial cell layer that borders the heart chamber.
(b) a subendocardial layer that continues the connective tissue of the myocardial connective tissue layer. This subendocardial layer houses the heart’s impulse-conduction mechanism.
The heart is a muscular organ in vertebrates that pumps blood to various areas of the body. It circulates blood by causing rhythmic contractions. The heart’s wall is made up of three layers: the epicardium (outermost), the myocardium (middle), and the endocardium (innermost) (innermost).
Cardiac Muscle Histology
It is critical to comprehend the meaning of cardiac muscles. In a nutshell, cardiac muscles are striated, involuntary muscles made up of cardiac muscle cells, or cardiomyocytes.

One of the three types of muscles identified in vertebrates are cardiac muscles (the other two being skeletal muscles and smooth muscles). Cardiac muscles have certain characteristics of both smooth and skeletal muscles. Cardiac muscles, like skeletal muscles, are striated and may cause powerful contractions as well as begin continual contractions. Cardiac muscles, on the other hand, have certain distinct features.

The cardiomyocytes are attached to the fibrous skeleton of the heart in a helical or overlapping spiral arrangement. This helical pattern produces a three-dimensional structural network that is complicated.
Cardiac muscle fibres are elongated cylindrical in form, with a length of 50–100 m and a width of 10–25 m. The muscle fibres are made up of discrete quadrangular cells with a clear oval nucleus in the centre. Muscle cells that are rectangular in shape are frequently branched and connected end to end to create a syncytium.
An intercalated disc is formed when two cardiac muscle cells come together to produce a unique junctional complex. Three key components are included in these intercalated discs:
1. Desmosomes connect the cytoskeleton’s intermediate filaments.
2. Gap junctions with low electrical resistance that allow excitation to spread.
3. Adhering junctions, also known as fascia adherens, are linkages between actin filaments that allow contraction to be transmitted.
An intercalated disc is a structural term that refers to the double membranes created by closely linked cells and desmosomes joined by gap junctions. This is necessary for the transmission of electrical impulses from one cell to the next.
Gap junctions facilitate the electrical connection of muscle cells, allowing the heart muscles to pulse in unison. Cardiac muscle cells can create powerful, continuous, and rhythmic contractions on their own.
The autonomic nervous system and hormones, on the other hand, can affect the contractility of heart muscle cells. Intercalated discs appear as faint lines perpendicular to the long axis of the heart muscle fibres under a microscope.
A brown colour pigment situated in a perinuclear location may generally be detected in an adult human. The buildup of lipids, phospholipids, and proteins following lipid peroxidation is the brown colour pigment “lipofuscin,” which is called a “wear and tear” pigment.
The cardiac myocyte’s functional unit for contraction is the sarcomere. The contractile fibres of the sarcomeres are encircled by transverse discs known as Z-bands within each myocyte. A number of sarcomeres are stacked end to end and circumferentially in each myocyte, producing a “cable effect” within the cell.
Myosin and actin are two essential proteins present in heart muscle cells. The heavy filaments are made up of myosin, whereas the thin filaments are made up of actin. These two proteins work together to produce the myofibrillar filament, which is responsible for contractile activity in cardiac muscle tissues.
Due to the high energy demand for regular contractions, cardiac muscle cells’ sarcoplasm (i.e., the cytoplasm of cardiac myocytes) is unusually abundant in mitochondria. The cardiac myocytes use oxidative phosphorylation to satisfy their energy needs. As a result, these muscles demand a constant supply of oxygen. Coronary arteries transport blood to the myocardium. Glycogen granules are also found in the myofibrils to support the increased energy demand.
The myocardial has the highest oxygen demand and is the most severely impacted by reduced blood flow. Ischemia, or a reduction in blood flow, can be dangerous for these muscles. Cardiovascular muscles are also resistant to exhaustion. Myogenic in nature, cardiac muscles generate their own action potential. However, some modified muscle cells are specialised to generate the stimulus for the heartbeat and convey the impulse to various parts of the myocardial system.
The Sinoatrial node, atrioventricular node, bundle of His, and Purkinje fibres are all specialised cells that make up the cardiac conduction system. Contractile cells make up 99 percent of the myocardium, whereas the myocardial conducting system makes up only 1% of the cells.
Conducting myocardial cells are specialised muscle cells that work similarly to neurons. The action potential is initiated and distributed throughout the heart by these conducting cells, and the contracting myocardial cells pick it up to pump the heart rhythmically and regularly.
Myocardium Function
It is critical to comprehend the function of the myocardial in order to comprehend the circulatory system. The cardiac muscles’ principal role is to promote heart contractions and relaxation.
The contraction of the cardiac muscles causes blood to be pumped from the ventricles to the rest of the body, while the relaxation of the cardiac muscles enables blood to enter the atrium. The heart’s pounding circulates blood throughout the body, ensuring that every cell and tissue receives oxygen and nutrients.
Cardiac muscles are primarily controlled by an independent neurological system that sends out timed nerve impulses to the heart cells, causing them to contract and relax in a regular manner.
Myocardium Physiology
The sarcoplasmic reticulum is stimulated by an action potential or nerve impulse, resulting in the release of calcium ions (Ca2+) into the cytoplasm. Troponin is induced to release tropomyosin by cytoplasmic Ca2+ ions. Tropomyosin that has been released changes its location, allowing myosin to bind to actin.
The stored ATP molecules are subsequently used by myosin to shorten each sarcomere. In the absence of the impulse, however, fast Ca2+ reabsorption into the sarcoplasmic reticulum occurs. Troponin re-anchors itself to tropomyosin in the absence of Ca2+, resulting in cardiac muscle cell relaxation. Twitch contractions occur in the heart muscle, with a protracted refractory time followed by short relaxation intervals. The heart has to relax in order to fill the atrium with blood for the next cycle to begin.
The force on the walls of the heart chamber is generated when all of the cardiac muscles act in unison. The cardiac muscle sheets are arranged in a planar pattern, with each muscle perpendicular to the others. When the heart contracts, it does so in numerous directions as a result of this. As a result of the contraction of the numerous layers of cardiac muscle fibre, the ventricle and atrium decrease from top to bottom and side to side. This causes the ventricles to pump and twist vigorously, pushing blood throughout the body.
It’s crucial to remember that cardiac muscle passes via aerobic metabolism, which mostly uses lipids and carbs.
Myocardial Dysfunction
Primary (genetic) and secondary (non-genetic) cardiac disorders are the two kinds of myocardial dysfunction (mostly acquired but may be precipitated for genetic reasons).
i. Cardiac Myopathy
Cardiomyopathies are heart illnesses caused by a faulty myocardium. Cardiomyopathy is one of the leading causes of illness and death worldwide. Cardiomyopathies are classified into five groups based on their clinical manifestations:
1. Dilated Cardiomyopathy: Ventricular dilation and congestive heart failure symptoms. Some of the primary contributing causes of this disease are arterial hypertension, myocarditis, alcohol misuse, or tachyarrhythmias.
2. Hypertrophic Cardiomyopathy: Hypertrophic cardiomyopathy is caused by ventricular hypertrophy, particularly in the left ventricle. This cardiomyopathy is thought to be passed on through the generations via the sarcomere.
3. Restrictive Cardiomyopathy: Scarring and stiffness of the ventricle walls, as well as impaired diastolic filling of the heart, are seen in this condition.
4. Arrhythmic Cardiomyopathy: Arrhythmic cardiomyopathy is caused by genetically faulty desmosomes. Non-ischemic cardiomyopathy is characterised by arrhythmias. The bulk of the instances recorded had an issue with the right ventricle, but there have been a few occurrences of left ventricles as well.
5. Unclassified Cardiomyopathy: Unclassified cardiomyopathy is a kind of cardiomyopathy that does not fit into any of the other categories.
ii. Myocardial Infarction (Heart Attack)
The heart tissues demand a large amount of oxygen and energy that is delivered continuously. The coronary arteries carry oxygen from the lungs to the heart. These arteries, on the other hand, are predisposed to the development of atheromas, which are aberrant deposits of fatty acids, cholesterol, and other cell detritus. If these atheromas are big, they impede or decrease blood and oxygen flow to the cardiac cells, resulting in a disease known as myocardial infarction or heart attack.

Myocardial ischemia is a condition in which the oxygen flow to the heart cells is reduced. The absence of oxygen causes heart tissue to die. However, the damaged region is healed as part of the human body’s natural physiological reaction. Though the mending causes fibrous tissue to grow at the location, this disrupts the usual propagation and conduction of excitatory impulses, resulting in aberrant cardiac contractions. These asynchronous contractions cause cardiac arrhythmias, or irregular heartbeats, such as ventricular fibrillation.
iii. Cardiomyopathy
Cardiomyopathy is a heart muscle illness that lasts a long time.
1. Ischemic Cardiomyopathy: Diffuse coronary artery disease can cause prolonged heart ischemia, resulting in dilated cardiomyopathy. This can happen after one or more silent myocardial infarction events.
2. Metabolic Cardiomyopathy: Diabetes mellitus causes high blood glucose levels, which leads to cardiac dysfunction and metabolic cardiomyopathy.
3. Peripartum Cardiomyopathy: Peripartum cardiomyopathy is defined as left ventricular systolic dysfunction occurring within one month after childbirth or five months after delivery.
4. Tachycardia-induced Cardiomyopathy: Tachycardia-induced cardiomyo-pathy is caused by a chronic and consistently high heart rate (> 110 beats per minute), as observed in prolonged ventricular tachycardia or atrial fibrillation. It can eventually lead to cardiac failure if it is not addressed.
If cardiomyopathy is not addressed, it might result in the following complications:
1. Heart Failure: Ineffective heart pumping leads to inadequate blood to satisfy your body’s demands, which can be fatal.
2. Blood Clots: Blood clots can form, and these clots can limit blood supply to organs such as the heart and brain, finally leading to stroke.
3. Valve Problems: Cardiomyopathy can cause the heart to expand, causing the heart valves to close incorrectly.
4. Cardiac Arrest and Rapid Death: Cardiomyopathy can cause cardiac arrhythmias, which can cause fainting or death.
iv. Myocarditis
Myocarditis is caused by inflammation of the myocardium. This might be due to a number of factors, including viral infection (infectious myocarditis), toxic chemicals, medication allergies, bacterial, fungal, or parasite infection, and an autoimmune disease. In myocarditis, both cardiomyocytes and cardiac vascular endothelial cells can be damaged and lost. The white blood cells infiltrate the heart muscle wall as a result of this.
Interstitial cardiac fibrosis, wall motion anomalies, arrhythmias, heart failure, myocardial infarctions, decreased ejection fraction, and sudden cardiac death can all occur as a result of this. Chest discomfort, dyspnea, and flu-like symptoms are common symptoms of myocarditis, although it can also be asymptomatic.
v. Heart Failure
Heart failure or congestive heart failure, is a frequent end-stage route and symptom of cardiac dysfunction that can occur for a number of pathophysiological reasons. Heart failure occurs when the heart is unable to pump enough blood throughout the body, causing congestion, decreased organ perfusion, and functional impairment. Heart failure can be classified as acute or chronic, right heart vs. left heart, or systolic vs. diastolic, depending on the cause, location, and duration.
Each of these disorders has its own clinical manifestations and features. Myocardial injury or infarction, persistent hypertension, valve dysfunction, arrhythmias, cardiomyopathies, and other causes and risk factors can all lead to heart failure. Shortness of breath, extreme fatigue, and leg edema are all frequent signs of coronary heart failure. The use of medicines such as ACE inhibitors and beta-blockers, among other things, is crucial in the treatment of heart failure.
vi. Perioperative Myocardial Injury
Perioperative myocardial damage is a myocardial complication that can develop after non-cardiac surgery and is often underappreciated. It’s important to emphasise that this condition is not the same as a myocardial infarction. Perioperative myocardial damage is more likely in patients under the age of 65 who have a history of atherosclerotic disease.
There is a significant rise in cardiac troponin T plasma concentration in this situation (hs-cTn). This disease is frequently diagnosed and exhibited without the presence of chest discomfort, dyspnea, or other classic heart damage signs. Because most of the typical symptoms are absent, this disease is frequently misdiagnosed.
It is critical to do hs-cTn screening perioperatively to rule out the occurrence of this syndrome. The risk of 30-day death after noncardiac surgery has been demonstrated to be substantially increased by perioperative myocardial damage.
Biological Importance of Myocardium
The heart is the body’s primary pumping organ. The pumping of blood throughout the body is caused by the contraction and relaxation of the heart. The cells and tissues of the body require a certain quantity of oxygen, which is provided by the circulating blood, for optimal functioning.
The myocardium, or cardiac muscles, are in charge of the heart’s rhythmic and continual contraction and relaxation, or pumping activity. Cardiac muscles are one of the first embryonic organs that form and operate throughout life. These muscles are part of a complicated system that includes coronary arteries, cardiac lymphatics, and autonomic nerves.
Cardiomyocytes make up the heart’s thickest layer. The myocardial is such a vital organ in the body that its malfunction can be fatal. Cardiovascular disease is the biggest cause of mortality in the globe. The myocardium is involved in a variety of cardiac disorders, resulting in contractile dysfunction, cell death, and ventricular pump failure.
Myocardium Citations
- Application of Stem Cell Technologies to Regenerate Injured Myocardium and Improve Cardiac Function. Cell Physiol Biochem . 2019;53(1):101-120.
- A Contemporary Look at Biomechanical Models of Myocardium. Annu Rev Biomed Eng . 2019 Jun 4;21:417-442.
- Therapeutic Cardiac Patches for Repairing the Myocardium. Adv Exp Med Biol . 2019;1144:1-24.
Share
Similar Post:
-

Simple Diffusion vs Facilitated Diffusion
Continue ReadingSimple Diffusion vs Facilitated Diffusion
The movement of molecules from the plasma membrane with the help of transporter protein such as carrier is called as facilitated diffusion. However, in simple diffusion, there is movement of the molecules, but they don’t require the assistance of membrane proteins, and takes place due to the electrochemical difference between the two sides.
The gradient concentration is required in simple diffusion for the driving force to act, whereas in facilitated the solute concentration variation through the membrane is the driving force responsible for facilitated diffusion.
Although majority of facilitated diffusion does not suffice the need of ATP, however in few cases it does require ATP. But in simple diffusion there is no ATP need in this passive transport type of simple diffusion. Facilitated diffusion take place due to the exactitude between the carriers and the solute, however there is no selectivity of solutes in simple diffusion.
The speed is quite high in facilitated diffusion, whereas in simple diffusion its quite low. Inhibitors cannot stop the simple diffusion, whereas in facilitated diffusion it is possible due to distinct inhibitors.
Kinetic energy along with concentration gradient helps to carry out simple diffusion and similarly in facilitated diffusion. In facilitated diffusion molecules can progress in both the direction i.e., towards or against the concentration gradient.
However, in simple diffusion, the shift is restricted towards the gradient. The molecules which can pass through are water soluble huge molecules through the plasma membrane in facilitated diffusion, whereas in simple diffusion, tiny water-soluble molecule can pass through.
Channel proteins are not required in simple diffusion as they can diffuse through membrane surface, whereas they are required in facilitated diffusion resulting pores development and molecules can progress.
Example of facilitated diffusion are movement of substances like amino acid and glucose from blood to cell, in the blood transportation of oxygen, and various ions like calcium and potassium. In simple diffusion, fusing of atmospheric gases, taking up of nutrients by microorganism, gases swapping taking place between the blood and lungs are some examples.
Simple Diffusion vs Facilitated Diffusion Citations
Share
Similar Post:
-
Polygenic Trait: Definition, Types, and Examples
Continue ReadingPolygenic Trait Definition
A polygenic trait is a characteristic, sometimes we call them phenotypes, that are affected by many, many different genes. A classic example of this would be height.
What is a Polygenic Trait?
A polygenic trait is one in which a number of non-allelic genes play a role. These sorts of genes are referred to as polygenes. They are a collection of genes that, when activated, express as a single unit. Each of these has an influence on the characteristics as a whole. Nonetheless, it is difficult to differentiate the influence of a single gene, especially when a polygenic trait comprises many genes.
The phenotypic character that results is frequently an intermediate of heritable characteristics, although traits at the extremes are less common than intermediates. As a result, the polygenic trait distribution may be represented as a bell-shaped pattern with continuous fluctuation.
The various trait outcomes can not be readily and straightforwardly divided into groups, such as white or black, because of the broad range of trait variances, but rather by a wide spectrum, such as light to dark.
Polygenic characteristics in humans include height, skin colour, hair colour, and eye colour. Polygenic diseases include type 2 diabetes, coronary heart disease, cancer, and arthritis. However, polygenes can be impacted by environmental variables, so these circumstances are not solely genetic.
Polygenic Trait Etymology
The phrase polygenic derives from the words poly, which means “many,” and genic, which means “of genes.”
Polygenic Trait vs Mendelian Inheritance
A polygenic trait is one that develops as a result of polygenic inheritance. A non-Mendelian inheritance is one that does not obey Mendelian rules. Gregor Mendel, an Austrian monk and botanist, proposed the Mendelian rules. From 1856 until 1863, his breeding efforts and research on garden pea plants went undetected.
They were only discovered in the early twentieth century. More than three decades later, separate investigations by Erich von Tschermark, Hugo de Vries, Carl Correns, and William Jasper Spillman confirmed Mendel’s results. Monogenic inheritance, in which only one pair of alleles or one gene is involved, is an example of Mendelian inheritance.
The phenotypic ratio of a test cross involving a single pair of alleles may be easily predicted using a Punnett square because it follows Mendelian rules such as the Law of Unit Characters, the Law of Segregation, and the Law of Independent Assortment.
However, additional research revealed that some modes of inheritance and the phenotypic ratio that resulted did not follow these principles. Polygenic inheritance is one of them. This is because this kind of inheritance is regulated by several genes (called polygenes), which can be found at various loci on different chromosomes and are not controlled by a single gene (or one pair of alleles).
These polygenes are more likely to be expressed together in order to create a certain phenotypic characteristic. A polygenic trait is a characteristic that is created by the expression of several genes. The Punnett square would indicate larger child differences from a test cross in polygenic inheritance, and hence would not be as clear as it is in monogenic inheritance.
Monogenic vs Polygenic Trait
As previously stated, a monogenic trait is one that is caused by the expression of a single gene or a pair of alleles. The seed colour of the garden pea would be an example of this in one of Mendel’s breeding experiments. The progeny of a cross between a true-breeding yellow-seeded pea and a true-breeding green-seeded pea generated exclusively yellow seeds.
The green seed characteristic resurfaced in the following generation (F generation), reappearing at a 3:1 ratio, meaning that for every three offspring generating yellow seeds, one produced green seeds. Mendel argued that the characteristic that was expressed (yellow) was dominant, while the one that was masked (green) was recessive, based on these results.
A monogenic characteristic, on the other hand, would be more forthright and may be divided into two groups, yellow or green in this example.
A polygenic trait is one that is caused by the expression of several genes. These genes seemed to have an additive influence on the offspring’s phenotypic.
Consider it a painting on an art canvas made by combining various colours and intensities. As a result, a polygenic character is a polygenic activity that occurs across time. When a single dominant allele is present, its expression is limited to a single unit rather than the entire characteristic.
As a result, a polygenic trait is quantitative as opposed to a qualitative monogenic trait. Because the polygenic characteristic is caused by many genes, the phenotypic ratio of the F generation would deviate from 3:1. Despite the fact that several genes influence a characteristic, their separate impacts are difficult to identify.
A polygenic trait’s sensitivity to environmental influences is another characteristic. Environmental factors, in addition to polygenes, may influence the polygenic characteristics.
Bell-shaped Distribution
When a monogene is expressed, it creates discontinuous variation; when a polygene is produced, it produces continuous variation. An intermediate type of polygenic characteristics is often exhibited. Only a few dominant and recessive types exist. As a result, frequencies and ratios are less effective in forecasting polygenic differences than they are in predicting monogenic differences.
Variations in polygenic inheritance are calculated and evaluated using variances, covariances, and averages. Polygenic character characteristics have a consistent continuous range of variation in their frequency (e.g. from the lowest to the highest, the thinnest to the thickest, the shortest to the longest, the brightest to the darkest, and so on.).
To put it another way, the range of variance is distributed in a bell-shaped pattern. As a result, polygenes open up a lot of options in terms of phenotypic characteristics.
Polygenic Trait Examples
A large number of human characteristics are polygenic. Height, skin colour, and eye colour are examples of polygenic characteristics expressed in humans. Polygenes have the benefit of generating a broader range of phenotypic and genotypic variability in the population.
Several genes control human height, resulting in a broad variety of heights in a community. A genome-wide association analysis discovered 697 genetic variations in 423 genomic loci that have a role in determining an adult human’s height. Non-genetic variables (such as diet) can impact the characteristics in addition to genetic predisposition.
As a result, predicting the height of the children based on the heights of the parents is difficult. Despite having a tall father, the kid may be short. Similarly, a tall child can be conceived by two short parents. In certain circumstances, the child’s height will fall somewhere between the parents’.
Skin colour, hair colour, and eye colour are all polygenic characteristics. These characteristics are determined by how much melanin is produced and deposited by the body. A person with many alleles related to melanin synthesis and deposition will have a dark complexion on their skin, hair, and eyes.
An individual with alleles for melanin synthesis and deposition in the skin but no alleles for melanin in the eyes, for example, will have a darker skin colour but a lighter eye colour. An individual with fewer alleles for melanin synthesis and deposition, on the other hand, will have a lighter complexion.
It’s important to distinguish between a polygenic trait and a codominant characteristic. Human blood type AB, for example, is not a polygenic characteristic. It’s more of a case of dominance. Blood type AB people have dominant alleles for A and B antigens on their red blood cells, which means they are expressed together.
Polygenic Trait Disorders
Polygenes produce a genetic condition known as polygenic disease. Type-2 diabetes is an example of a polygenic disorder that can progress to illness. Polygenes are thought to be the majority of the genes involved in this disease.
According to recent research, there are more than 36 genes involved in the increased risk of type 2 diabetes. The inheritance of the TCF7L2 allele, for example, can raise the risk of diabetes by 1.5 times.
Other medically significant polygenic diseases include hypertension, coronary heart disease, cancer, arthritis, and mental illness, in addition to type-2 diabetes.
These disorders, on the other hand, aren’t totally hereditary. There might also be environmental variables at play that enhance a person’s chances of contracting any of them. Nonetheless, because they are polygenes that operate cumulatively, inheriting many of the genes associated with them raises the risk.
Polygenic Trait Citations
- Polygenic risk scores: from research tools to clinical instruments. Genome Med . 2020 May 18;12(1):44.
- The personal and clinical utility of polygenic risk scores. Nat Rev Genet . 2018 Sep;19(9):581-590.
- An Expanded View of Complex Traits: From Polygenic to Omnigenic. Cell . 2017 Jun 15;169(7):1177-1186.
Share
Similar Post:
-
Pioneer Species: Definition, Types, and Examples
Continue ReadingPioneer Species Definition
Pioneer Species are those organisms that begin the formation of an ecological community in a region where no living forms currently exist.
What is a Pioneer Species?
Areas that are completely barren, devoid of nutrients, and inhospitable provide slim (to none) possibilities for any living form to establish itself. But to the rescue comes the resilient, photosynthetic, widespread, fast-reproducing, orthodox-seeded pioneer community, with high dispersibility rates, shorter life cycles, and great tolerance…
So, if someone asks us to describe pioneer species, we can quickly describe their basic characteristics and explain how ecological succession occurs.
In primary succession, pioneer species are the first to colonise a bare substrate, whereas in secondary succession, they are the first to colonise a devastated environment.
Examples include
(1) a pioneer lyme grass (Leymus arenarius) on a sand-covered plain,
(2) pioneer plant species (e.g. swordfern, Polystichum munitum, and the moss Racomitrium ericoides) that thrived in a newly formed habitat created by a solidified lava flow, and
(3) pioneer plant species that colonised an area that had been cleared.
Pioneer Species Example
A thorough collection of instances has been compiled. To learn more about them, look at the image below. Pioneer germs, fungi, and animals only enter when pioneer flora and lichens have mastered their tasks. Soil invertebrates such as ants, worms, and snails, as well as some toads, are examples of pioneer fauna.
The Sword Fern (Polystichum munitum) is a Pteridophyta pioneer.
Features of Pioneer Species
1. Hardy in nature: Pioneer species are able to endure and trade in a variety of severe environmental circumstances.
2. Seeds- Orthodox and easy to germinate: Pioneer species have orthodox seeds, which are “seeds with less than 5% total moisture content that are nonetheless alive and have remarkable longevity.” This property aids pioneer species in reproducing even after years of hibernation. Desiccation is not a problem for them, and they may produce new plants following germination. These seeds are unaffected by low moisture content.
3. Seed Germination- Light-Induced: The seeds of pioneer species are often “photoblastic,” meaning they germinate when light is stimulated. Any seed will germinate if it is given ideal moisture, nutritional, and other environmental circumstances, but these seeds don’t have much demand in desolate regions. Their only requirement for germination has evolved to be “light stimulation.”
4. Life Cycle- Short: Any biological body is created with the ultimate goal of “species perpetuation” in mind. Pioneer species have evolved to have a brief life cycle since desolate environments give little opportunity for any creature to enjoy a happy time for a long time. This is a sign that they are in the early stages of their reproductive lives. Pioneer species reach reproductive maturity quickly, regardless of how they generate progeny (sexual or asexual).
5. Pollination and Seed Dispersal- Both via wind: In the same way that an unfriendly habitat is bad for any species, it is also bad for pollinators (whether they are birds, insects, bats, or animals). Wind pollination is the only viable option. The majority of sexually reproducing pioneer species, for whom pollination is an important stage in gamete fertilisation, are pollinated by the wind. Furthermore, the wind is used to disperse their seeds.
6. Rates of Seed Production and Dispersal- High: Pioneer species’ seeds are extremely viable, generated in a geometric pattern (in huge numbers), and have a high dispersion rate. Such dispersion rates are required to colonise a nutrient-deficient terrain.
7. Propagule Size- Small: Small propagules make it easier to disperse and achieve succession goals. Small seed or propagule size also enhances germination chances since they can get “caught” in small cracks, holes, and traps during hostile periods.
8. Wide Range- Both ecological and geographical: This broadens the distribution and helps primary succession in regions impacted by a variety of causes.
9. Major Mode of Reproduction- Asexual > Sexual: Because sexual reproduction is more energy-intensive and time-consuming, it isn’t truly a viable option for pioneer species. Although there are certain animals that have a sexual mode. The asexual mode, on the other hand, is more popular due to the benefits it provides.
Certain lichens and algae are widespread species that can thrive in a variety of environments, making them the most common pioneer species, or initial settlers, after a disturbance. Because the new environment is likely to have soil with fewer nutrients and be primarily exposed to light energy, the pioneer plant species are often photosynthetic.
It’s also more likely that wind pollination is used by pioneer plant species. Furthermore, rather than sexual reproduction, most people reproduce asexually. The pioneer species may eventually give nutrients to the soil, resulting in a better environment for the following species.
Pioneer Species and Ecological Succession
It is critical to comprehend ecological systems, the formation of ecological communities, and ecological successions in order to create conceptual clarity about pioneer species. The biological interactions between the many parts of the natural system, as well as their various interrelationships, are referred to as ecological systems.
The way an ecological system is constructed influences how it will work, as well as its fundamental requirements, long-term viability, and success. An ecological community is based on how “often” certain species occur together in a given region.
The species share comparable environmental conditions and resource scarcity/abundance. The community’s equilibrium is determined by how they affect one another. All variables, processes, and interrelationships within a community that regulate its evolution across time are referred to as ecological succession. It is primarily concerned with the “structural” evolution of a biological community through time.
Every physical, chemical, and biological entity changes over time, and ecological succession describes these changes. “Changes in community skeleton” – how different species evolve, how one’s evolution affects another’s, how coevolution occurs, and how organisms gradually adapt to thrive in harsh environments.
Types of Ecological Successions
i. Primary Succession
Primary succession occurs when an organism lives, thrives, and reproduces in a region where no other organism has ever lived, flourished, or reproduced.
Only pioneer creatures, especially “only pioneer plants,” can lead to the establishment of a friendly habitat in this case. Characteristics of every pioneer organism capable of bringing about primary succession:
1. Any barren area would be devoid of pre-existing organic compounds, making organic compound oxidation for energy purposes impossible.
2. Because there are no pre-existing autotrophs on barren ground, the heterotrophic mechanism of carbon derivation is clearly removed.
3. Any desolate terrain would almost certainly lack any biological source of electrons (even inorganic ones are unlikely… But if some minuscule probability is included, it’s still only an inorganic source!).
As a result, in primary succession, the pioneer species must be a plant—a photo-auto-lithotroph. They colonise bare surfaces (without soil) and then form ecological communities.
Primary Succession Examples
Photo-auto-lithotrophs include only plants and a specific type of algae known as “blue green algae/Cyanobacteria.” As a result, they are the only pioneer species responsible for initial succession. Apocalyptic habitat loss occurs in areas impacted by large landslides, fires, volcanic eruptions, or flooding. The topsoil and layers underneath it are eroding in certain locations.
There is no energy/carbon/electron source remaining in such regions that can support life other than photo-auto-lithotrophic life. Another aspect worth mentioning is the “essence of a finite resource-NITROGEN.” As a result, several of these pioneers fixed nitrogen.
Because they are photo-auto-lithotrophic and nitrogen-fixing, cyanobacteria are primarily responsible for primary succession in the most severe environments.
Lichens are the first species to appear in primary succession, and they have the unique ability to colonise bare rocky surfaces.
ii. Secondary Succession
Unlike the barren and previously deserted places, certain areas require re-establishment following a disturbance that “wiped away” a full-fledged natural population. The secondary succession is this re-establishment. Some soil and previously existing plants are still present in these locations. There are fewer resource battles in these regions, and pioneer species have an advantage.
We can list angiosperm trees and shrubs as pioneer species in secondary succession if requested. These have some of the highest growth and community development rates in the country. Pioneer species in secondary succession are not required to be photo-auto-lithotrophic.
Secondary Succession Example
Microbial and invertebrate taxa have just recently been added to the pioneer species list. Photo/chemo, auto/hetero, litho/organo trophs are all possibilities. This emphasises an essential point: secondary succession occurs in areas where certain nutrients are already present in the substrate.
Secondary succession occurs in places like deforested regions, logged woods, wind-affected areas, and so on. As a result, numerous microbiological species (bacteria, archaea), invertebrates, and tree species, such as Betula spp. (birch tree species) and Alnus spp. (alder tree species), serve as pioneer species in secondary succession.
An Interesting Fact About Pioneer Species
Did you know that the 1986 Chernobyl Nuclear Power Plant Disaster in Pripyat, Soviet Union, which displaced humans, animals, and other species, gave birth to a new fungus that “feeds on radiation”? Yes… Scientists investigating the region discovered “a pioneer fungus” that is an extremophile suited to strong radiation and has a remarkable capacity to eat it rather than be harmed by it (unlike other organisms).
This fungus species is pushed to the most severe radioactive locations, similar to how plants exhibit phototropism (the ability to be driven towards a light source). This species’ main and secondary metabolic products, which have incredible lytic and enzymatic activity, provide this quality! Who knows how many more pioneer species have been generated and are still being investigated in that catastrophic place… How many more pioneers will be born as a result of this?
Pioneer Species Citations
- How lichens impact on terrestrial community and ecosystem properties. Biol Rev Camb Philos Soc . 2017 Aug;92(3):1720-1738.
- Changes through time: integrating microorganisms into the study of succession. Res Microbiol . 2010 Oct;161(8):635-42.
- Gopher mounds decrease nutrient cycling rates and increase adjacent vegetation in volcanic primary succession. Oecologia . 2014 Dec;176(4):1135-50.
Share
Similar Post:
-

Null Hypothesis: Definition, Types, and Examples
Continue ReadingNull Hypothesis Definition
The term “null hypothesis” refers to “a generally held belief (such as that the sky is blue) that researchers seek to refute or invalidate.”
A null hypothesis is defined as “a statistical theory proposing that no statistical link exists between given observed variables” in more technical terms.
In biology, the null hypothesis is used to refute or invalidate a widely held view. The researchers conducted the research with the goal of refuting a widely held notion.
A null hypothesis is an assumption or assertion that a difference seen between two samples of a statistical population is attributable to chance rather than systematic reasons. It is the hypothesis that will be tested statistically to see whether it can be rejected, indicating that the alternative hypothesis is correct.
A null hypothesis is one that is valid or believed to be true unless it is disproved by a statistical test. As a result, one cannot state that a null hypothesis is “accepted,” but rather that it “cannot be dismissed,” since statistical evidence supports it.
A null hypothesis that is disproved, on the other hand, is said to have been “rejected.” Ronald Fisher, an English geneticist and statistician, invented the term. H0 is the symbol.
What is Null Hypothesis?
A hypothesis is a theory or supposition that is supported by insufficient evidence. For confirmation, further research and testing are needed. A hypothesis might be incorrect or true depending on how many experiments and tests are conducted. It may either be proven false or true.
Susie, for example, believes that mineral water aids plant development and nutrition more than purified water. She did this experiment for over a month in order to verify her idea. She used mineral water on some plants and distilled water on others.
The hypothesis is called a null hypothesis when there are no statistically significant connections between the two variables. The researchers are attempting to debunk such a theory. The null hypothesis in the following plant example is that there are no statistical correlations between the types of water provided to plants for growth and sustenance.
An investigator often tries to refute the null hypothesis by explaining the relationship or link between the two variables.
The alternative hypothesis is the polar opposite and reversal of the null hypothesis. The alternative hypothesis for plants is that there are statistical correlations between the many types of water that are provided to them for development and sustenance.
The following example illustrates the distinction between null and alternative hypotheses:
1. Alternative hypothesis is that the world is spherical.
2.The globe is not round, according to the null hypothesis.
Copernicus and many other scientists attempted to disprove the null hypothesis. They persuade individuals that alternative ideas are right and true through their studies and tests. People will not accept them unless they can empirically disprove the null hypothesis, and they will never consider the alternative hypothesis true and accurate.
Susie’s alternative and null hypothesis is as follows:
1. Null Hypothesis: There is no difference in the development and sustenance of these two plants if one is watered with distilled water and the other with mineral water.
2. Alternative Hypothesis: If one plant is watered with distilled water and the other is watered with mineral water, the mineral water-watered plant will grow and feed better.
The null hypothesis states that no statistically significant association exists. The relationship might exist between two sets of variables or within a single set of variables.
The null hypothesis is widely accepted as true and correct. Scientists work on many experiments and conduct a range of research in order to disprove or nullify the null hypothesis. They create an alternative hypothesis that they believe is right or true for this reason.
H0 is the symbol for the null hypothesis (it is read as H null or H zero).
This hypothesis is given the label null to clarify and emphasise that scientists are attempting to show it is untrue, i.e., to nullify it. It can sometimes perplex readers; they may misinterpret it and conclude that the sentence has no meaning. It appears to be blank, but it is not. Instead of calling it the null hypothesis, it’s more acceptable to call it a nullifiable hypothesis.
The scientific method is employed in science. It entails a number of distinct phases. These procedures are carried out by scientists in order to determine if a hypothesis is true or incorrect. This is done by scientists to ensure that the new theory will not have any limitations or inadequacies. Experiments are conducted with both alternative and null hypotheses in mind, ensuring that the study is safe.
If a null hypothesis is not included or a part of the investigation, it has a negative as well as a negative influence on the research. It appears that you are not worried about your research and simply want to impose your findings as accurate and true if the null hypothesis is not included in the study.
In statistics, the initial step is to create alternative and null hypotheses based on the problem. The route to a solution is made easier and less hard by breaking the problem down into tiny pieces.
There are two phases to writing a null hypothesis:
1. Begin by posing a hypothetical inquiry.
2. Second, rephrase the question such that there appear to be no connections between the variables.
In other words, make the assumption that the therapy has no impact.
Null Hypothesis Examples
The typical recuperation period following knee surgery is eight weeks. According to one study, if patients go to a physiotherapist for rehabilitation twice a week instead of three times a week, the recovery period will be lengthened.
However, if the patient visits three times for rehabilitation instead of two, the recovery period would be shorter.
STEP 1: Examine the theory for a flaw. The hypothesis might be a phrase or a statement. The hypothesis in the above case is:
“Knee rehabilitation is likely to take more than eight weeks.”
STEP 2: From the hypothesis, formulate a mathematical statement. Because averages may be written as, the null hypothesis formula will be.
H1: μ>8
The hypothesis is identical to H1. The average is indicated by and > that the average is larger than eight in the preceding equation.
STEP 3: Describe what will happen if the hypothesis is incorrect. For example, the rehabilitation time may not last more than eight weeks.
There are two alternatives for recovery: either it will take less than or equal to 8 weeks, or it will take longer than 8 weeks.
H0: μ ≤ 8
The null hypothesis is H0. The average is represented by, and signifies that the average is less than or equal to eight in the preceding equation.
What happens if the scientist doesn't know what the results will be?
Problem: A researcher is studying the impact and influence of extreme exercise on individuals who have had knee surgical operations. The possibilities are that the activity will either help or hurt your recuperation. The average recuperation time is 8 weeks.
STEP 1: Form a null hypothesis, i.e., that the exercise has no impact and that the recuperation time is still almost 8 weeks.
H0: μ = 8
The null hypothesis is identical to H0 in the preceding equation. The average is indicated by, and the equal sign (=) indicates that the average is equal to eight.
Step 2: Create an alternate hypothesis that contradicts the null hypothesis. What will happen, in particular, if therapy (exercise) has an effect?
H1: μ≠8
The alternative hypothesis is equivalent to H1. The average is indicated by, and the not equal sign () indicates that the average is not equal to eight in the preceding equation.
Significance Test
A significance test is used to get a plausible and likely explanation of statistics (data). The null hypothesis is unsupported by evidence. It is a piece of information or a statement that comprises numerical population numbers. The information can be presented in a variety of formats, such as meanings or proportions. It might be an unusual ratio or a discrepancy in proportions and averages.
The P-value is the most important statistical outcome of the null hypothesis significance test.
1. P-value = Pr (data or more extreme data | H0 false)
2. | = “assumed”
3. Pr stands for probability.
4. H0 denotes the null hypothesis.
The formation of an alternative and null hypothesis is the first stage of Null Hypothesis Significance Testing (NHST). The research question may be succinctly described in this way.
1. Null Hypothesis: Treatment has no impact, there is no difference, and there is no link.
2. Alternative Hypothesis: successful therapy, distinction, and link.
If the null hypothesis is proved to be false by experimentation, researchers will reject it. Until it is proven erroneous or untrue, researchers regard the null hypothesis as true and correct. The researchers, on the other hand, are attempting to bolster the alternative theory. A sample is subjected to the binomial test, which is followed by a series of tests (Frick, 1995).
STEP 1: Carefully evaluate and read the study topic before formulating a null hypothesis. Check the sample to see if the binomial proportion is supported. If there is no difference, determine the binomial parameter’s value.
The null hypothesis should be written as:
H0: p= if H0 is true, the value of p
Calculate the sample proportion to see how much it differs from the planned data and the null hypothesis value.
STEP 2: Locate the binomial test that falls under the null hypothesis in test statistics. The exam must be based on exact and comprehensive probability. Make a list of PMF that apply if the null hypothesis is proven to be true.
When H0 is true, X~b(n, p)
N = size of the sample
P = assume value if H0 proves true.
STEP 3: Determine the value of P, which is the likelihood of the data being seen.
When H0 is true, X~b(n, p)
N = size of the sample
P = assume value if H0 proves true.
STEP 4: Describe and describe the results or consequences in a descriptive manner.
An increase in the P value or a rise in the P value = Pr(X ≥ x)
X = observed number of successes
P value = Pr(X ≤ x).
Take note of the following:
1. Sample percentage
2. P-value
3. Differences in direction (either increases or decreases)
The statistical significance of the null hypothesis cannot be explained or expressed if the value of P is tiny, such as 0.10.
Perceived Problems With the Null Hypothesis
The main difficulties that impact the testing of the null hypothesis are variable or model selection and, in some circumstances, a lack of information. The null hypothesis’ statistical tests aren’t very powerful. When it comes to significance, there is some randomness. Gill (1999). The major problem with testing null hypotheses is that they’re all incorrect or untrue on the surface.
There is an additional issue with the a-level. This is an underappreciated but well-known issue. Because the value of a-level has no theoretical basis, typical values such as 0.q, 0.5, or 0.01 are subject to randomization. When a fixed value is utilised, two categories are formed (significant and non-significant). When there is a practical concern about the strength of the evidence connected to a scientific subject, the question of randomised rejection or non-rejection arises.
The P-value is crucial when testing the null hypothesis, but it has a flaw as an inferential tool and for interpretation. The chance of receiving a test statistic at least as severe as the observed one is the P-value.
The definition’s primary feature is that observed results are not reliant on a-value.
Furthermore, due to unseen outcomes, the evidence against the null hypothesis was exaggerated. More than merely a statement, the A-value has significance. It’s a detailed statement regarding the evidence based on the facts or outcomes that have been observed. P-values, too, have been determined to be undesirable by researchers.
They don’t like testing null hypotheses. It’s also obvious that the P-value is solely determined by the null hypothesis. It’s a type of computer-assisted statistics. The null hypothesis statistics and actual sample distribution are tightly connected in some exact experiments, but this is not achievable in observational research.
The P-value, according to some academics, is dependent on the sample size. A null hypothesis, even in a large sample, may be rejected if the real and exact difference is tiny. This illustrates the distinction between biological and statistical significance.
Another problem is the 0.1 fix a-level. A null hypothesis for a large sample may be accepted or rejected based on if a-level. There is still a possibility of Type I error if the size of the simple is infinite and the null hypothesis is proven true. As a result, this technique or procedure is not thought to be consistent or dependable.
Another issue is that precise information regarding the precision and magnitude of the predicted effect is unavailable. The only way to avoid this is to describe the effect’s magnitude and accuracy.
Null Hypothesis Examples
Null Hypothesis Example 1: Hypotheses in one categorical variable with one sample
Almost 10% of the human population prefers to perform tasks with their left hand, i.e., they are left-handed. Assume a researcher from the University of Pennsylvania claims that the majority of students at the College of Arts and Architecture are left-handed as compared to the overall population of individuals in general public society. There is just a sample in this situation, and the known population values are compared to the population percentage of sample value.
1. Research Question: In comparison to the general population, are artists more likely to be left-handed?
2. Response Variable: Classifying students into two groups. Left-handed people make up one group, while right-handed people make up the other.
3. Form Null Hypothesis: Arts and Architecture college students are no more likely to be left-handed than the general population (Lefty students in the Arts and Architecture college population account for 10% of the whole population, or p= 0.10).
Null Hypothesis Example 2: Hypotheses with one sample of one variable measurement
Diphenhydramine is a generic brand of antihistamine that comes in the form of a capsule with a 50mg dosage. The manufacturer of the medications is concerned that the machine has lost calibration and is no longer producing capsules with the proper dose.
1. Research Question: Does the suggested statistical data for the population’s mean and average dose differ from 50mg?
2. Response Variable: A chemical test that is used to determine the correct dose of an active substance.
3. Null Hypothesis: Typically, this trade name’s 50mg capsule dose (population average and mean dosage =50 mg).
Null Hypothesis Example 3: Two samples of one categorical variable in hypotheses
On a daily basis, a number of people choose vegetarian meals. Females, according to the researcher, prefer vegetarian meals to men.
1. Research Question: Does the evidence suggest that, on a regular basis, ladies (women) prefer vegetarian meals to males (men)?
2. Response Variable: Sorting people into vegetarian and non-vegetarian groups. Gender is a third factor that may be used to divide people into groups.
3. Null Hypothesis: is that there is no such thing as a null hypothesis. Those who enjoy vegetarian meals are not divided by gender. (% of women who eat vegetarian meals on a regular basis = % of males who eat vegetarian meals on a regular basis, or p women = p men.)
Null Hypothesis Example 4: Two samples of one measurement variable hypotheses
Obesity and being overweight is one of the most serious and severe health problems nowadays. A study is being conducted to see if a low-carbohydrate diet is more effective than a low-fat diet in terms of weight loss.
1. Research Question: Does the evidence suggest that a low-carbohydrate diet helps people lose weight more quickly than a low-fat diet?
2. Weight loss as a response variable (pounds)
3. Explanatory Variable: Low-carbohydrate or low-fat diet type
4. Null Hypothesis: When comparing the mean weight reduction of persons on a low carbohydrate diet to people on a low-fat diet, there is no significant difference. (Population means weight loss on a low-carbohydrate diet = population means weight loss on a low-fat diet).
Null Hypothesis Example 5: The relationship between two categorical variables hypotheses
A case-control experiment was carried out. Non-smokers, stroke patients, and controls are included in the research. The respondents were all of the same age and employment, and the query was whether or not someone in their immediate vicinity smoked.
1. Research Question: Does second-hand smoking make you more likely to have a stroke?
2. Variables: Variables are divided into two groups. (Patients with stroke and controls) (whether the smoker lives in the same house). If a person lives with a smoker, their chances of getting a stroke are enhanced.
3. Null Hypothesis: There is no link between being a passive smoker and having a stroke or a brain attack. (The odds ratio between stroke and passive smoking is 1).
Null Hypothesis Example 6: The relationship between two measurement variables hypotheses
1. Variables: The explanatory variable is stock acquired by non-management personnel the day before, and the response variable is daily price change data and information. These are two separate types of measurements. There are two main variables that may be measured.
A. Response Variable: Price fluctuation on a regular basis
B. Explanatory Variable: Non-management workers’ stock purchases
2. Null Hypothesis: The correlation and link between daily stock-buying by non-management workers ($) and regular stock price changes ($) = 0.
Null Hypothesis Example 7: Comparing the relationship between two measurement variables in two samples hypotheses
1. Research Question: Is there a linear relationship between a restaurant bill and the tip offered to the waiter? Is there a difference between dining and family restaurants in terms of this relationship?
2. Variables: There are two types of variables, each with its own set of characteristics. The tip amount is determined by the entire bill.
A. Explanatory Variable: the entire amount of the bill
B. Response Variable: the tip amount
3. Possible Null Hypothesis: In a family or dining restaurant, the link and association between the total bill quantity and the tip is the same.
Null Hypothesis Citations
- A review of issues about null hypothesis Bayesian testing. Psychol Methods . 2019 Dec;24(6):774-795.
- Macphail’s Null Hypothesis of Vertebrate Intelligence: Insights From Avian Cognition. Front Psychol . 2020 Jul 8;11:1692.
- Null hypothesis significance testing and effect sizes: can we ‘effect’ everything … or … anything? Curr Opin Pharmacol . 2020 Apr;51:68-77.
Share
Similar Post:
-
Primary Succession: Definition, Types, and Examples
Continue ReadingPrimary Succession Definition
Ecological succession refers to the gradual evolution of a group of species or a community through time, such as decades or millions of years. Typically, one dominating group of living forms has succeeded in establishing a stable climax community across a certain region.
What is Primary Succession?
A Primary succession is an ecological succession in which a group of species or a community colonises a freshly created region for the first time. Topsoil and organic materials are generally sparse in this formerly deserted, desolate region.
The pioneer species is the species that colonises an unoccupied region for the first time, and the pioneer community is the dominant community. Soon, a broader diversity of plants and animals will populate the region, leading to the formation of a climax community.
The species occupying the region might be replaced by a new ecological succession, called secondary succession, if disturbed or interfered with by a disruptive external or internal cause.
Because the region had previously been occupied during the first succession, the second succession might happen much faster, in decades or even hundreds of years, as opposed to thousands or even millions of years during the initial succession.
Primary Succession Etymology
Adolphe Dureau de la Malle, a French scientist, was the first to use the term succession in an ecological context. The term refers to the growth of plants following forest clear-felling.
Type of Primary Succession
The process starts with a bare rock produced by volcanic eruptions or receding glaciers in this figure. The pioneer species (lichens and moss) that grow on the rock are the next stage. These species’ death and subsequent decomposition contribute to the creation of soil.
Grass and herbaceous plants are the next category of plant invaders. After that, shrubs and bushes take their place, followed by trees. Animals inhabiting the region are growing more varied as the diversity of plant species improves.
However, when competition for sunshine, space, and nutrients increases, those that are better suited and more tolerant, such as “shade-tolerant trees,” survive and grow.
i. Primary Succession
A succession of prevailing species communities in a certain environment characterises both kinds. They differ in terms of the habitat’s ecological history and genesis.
When a group of species or a community colonises a barren, freshly created environment, for example, this is known as primary succession.
The formation of plant or animal communities in a location where there is no soil at first, such as bare rocks created by a lava flow, is an example of primary succession. The colonization of a barren region following a catastrophic landslide or newly exposed land from retreating glaciers are two more instances.
Another is the colonisation of difficult environments like sand dunes. Sand dunes are only habitable by a few highly specialised flora and animals due to their extraordinarily scorching temperatures.
ii Secondary Succession
When a previously inhabited region is colonised by a new dominant group of species or communities, this is known as secondary succession.
In secondary succession, new occupants take the place of earlier groups in a habitat that has been affected by an ecological disturbance. The source of the disruption might be external or internal. The recolonization of a burned-out region is an example of secondary succession.
The habitat type is another distinction between main and secondary successions. Living creatures colonise a barren terrain, which implies it lacks topsoil, in primary succession.
In secondary succession, on the other hand, living creatures will re-colonize a previously occupied region, resulting in topsoil containing organic materials from the previous occupants.
Primary Succession Process
Primary succession takes a long time to develop and complete, perhaps a thousand years or more. On the other hand, secondary succession frequently happens more quickly, taking just a decade or a hundred years. This is due to the fact that most living forms would find a freshly created region undesirable at first.
The newly created area, for example, would be devoid of soil and made up entirely of bare rocks. Primary succession begins at this stage. A sequence of physicochemical modifications must take place till they become more hospitable to life.
Pioneer species are species that may effectively establish and control a newly created or previously unoccupied territory. Pioneer communities are communities that have successfully developed and dominated newly formed or previously uninhabited land.
A community is an ecological unit made up of a collection of organisms or a population of several species that live in a certain region. A community can be a tiny population living in a small area (such as a pond) or a huge geographical region that defines a biome.
The colonisation phase of primary succession begins with the establishment of a pioneer village. Lichens, algae, and fungus are examples of pioneer species.
These species are more tolerant, and by breaking down rocks into tiny pieces, they eventually contribute to the creation of soil. They also provide organic materials for the environment. The region eventually became loaded with thin soil, making it suitable for the establishment of higher kinds of species.
Intermediate species are the following species that invade and dominate the region. Grasses and shrubs that flourish on thin soils are examples. A greater diversity of plants and tiny animals can occupy the region as the environment improves.
The formation of a climax community, or a community made up of even higher forms of life, such as shade-tolerant plants and taller trees that attract larger and higher types of animals, is the last step.
Secondary Succession Process
The second succession happens when the habitat is subjected to a disturbance that threatens the habitat’s occupants. Because the region is already populated by plants and animals, it will likely stay livable after the disruption, making re-colonization quicker and more accessible.
In secondary succession, top soil is found whereas is absent in primary succession. Shorter period is seen in secondary succession and longer duration in primary succession.
Example are retreated glaciers for primary succession and tornado’s, flood, fire are secondary succession. A third kind, known as cyclic succession, occurs when a group of species gradually replaces a previously dominating species over time without causing large-scale disruption.
Importance of Primary Succession
The main succession is critical for pioneering the region and creating suitable conditions for the establishment of additional plants and animals. It prepares the stage for future successions, since formerly flourishing organisms may become an important part of the soil.
Because pioneer species are more tolerant of adverse environments, they might take the available nutrients and transform them into a form that other life forms could utilise.
Primary Succession Citations
- How lichens impact on terrestrial community and ecosystem properties. Biol Rev Camb Philos Soc . 2017 Aug;92(3):1720-1738.
- Changes through time: integrating microorganisms into the study of succession. Res Microbiol . 2010 Oct;161(8):635-42.
- Gopher mounds decrease nutrient cycling rates and increase adjacent vegetation in volcanic primary succession. Oecologia . 2014a Dec;176(4):1135-50.
Share
Similar Post: